About
The Objective of LiLa
The LiLa project builds a Linked Data-based Knowledge Base of Linguistic Resources and Natural Language Processing (NLP) tools for Latin. The Knowledge Base consists of different kinds of objects connected via an explicitly-declared vocabulary for knowledge description.
LiLa collects and connects both existing and newly-generated (meta)data. The former are mostly linguistic resources (corpora, lexica, ontologies, dictionaries, thesauri) and NLP tools (tokenisers, lemmatisers, PoS-taggers, morphological analysers and dependency parsers) for Latin. These are currently available from different providers under different licences. With regard to newly-generated (meta)data, LiLa assesses a set of selected linguistic resources by expanding their lexical and/or textual coverage. In particular, LiLa (a) enhances a large amount of Latin texts with PoS-tagging and lemmatisation, (b) harmonises the annotation of the three Universal Dependencies treebanks for Latin, (c) improves the lexical coverage of the Latin WordNet and the valency lexicon Latin-Vallex, and (d) expands the textual coverage of the Index Thomisticus Treebank. Furthermore, LiLa builds a set of newly-trained models for PoS-tagging and lemmatisation, and works on developing and testing the best performing NLP pipeline for such a task.
Connections between the aforementioned types of data are edges labelled with a restricted set of values (metadata) taken from a vocabulary of knowledge description. The Knowledge Base thus consists of a set of connections between target and source nodes.
Model
The LiLa Knowledge Base is highly lexically-based. Lemmas are the key node type in the Knowledge Base. Lemmas occur in Lexical Resources (as lexical entries), but may have one or more (inflected) Forms. For instance, the Latin lemma puella, ‘girl’ has forms like puellam, puellis and puellas. Forms, too, can occur in lexical resources, for instance, in a lexicon containing all the word forms of a language (e.g., Thesaurus Formarum Totius Latinitatis, Tombeur1). Both Lemmas and Forms can have one or more graphical variants (condicio vs. conditio). The occurrences of Forms in real texts are Tokens, which are provided by Textual Resources. Texts in Textual Resources can be different editions/versions of the same Work (e.g., the various editions of the Orator by Cicero, possibly provided by different Textual Resources). NLP tools process either Forms (e.g., a morphological analyser) or Tokens (e.g., a PoS-tagger).
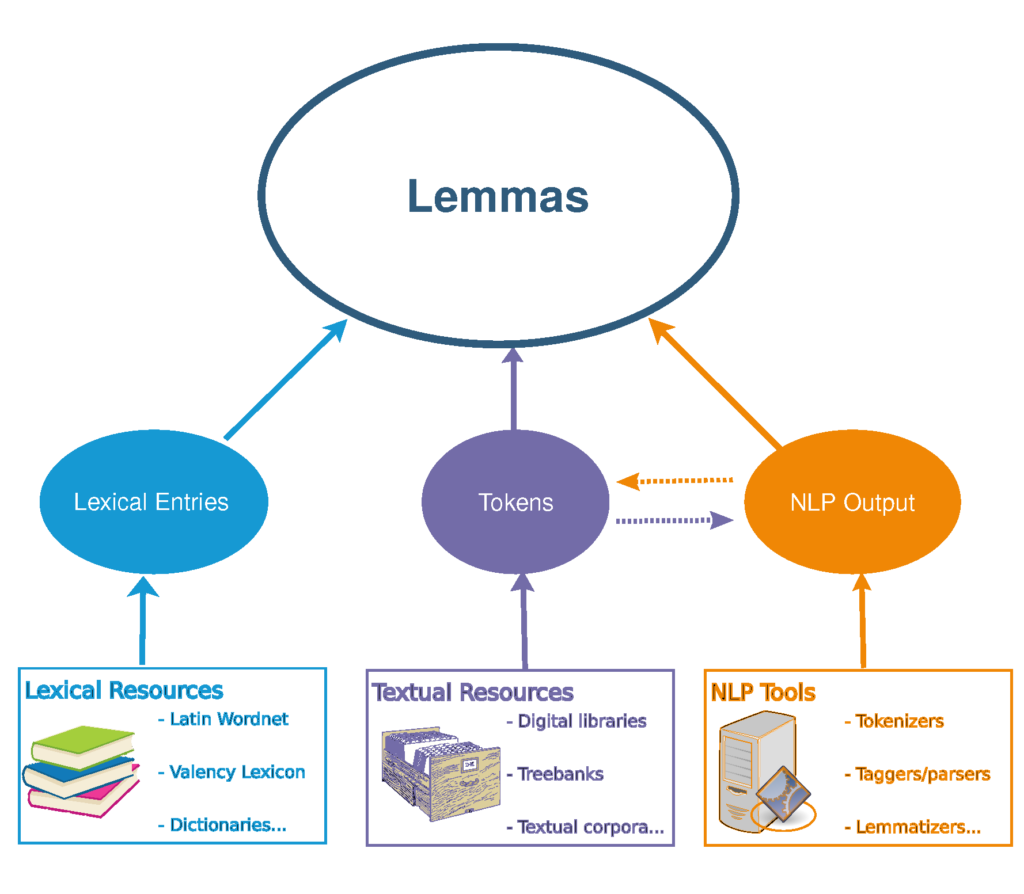
Work Packages
LiLa is articulated around five Work Packages (WPs).
Work Package 1 (months 1-24). Selecting and Improving Linguistic Resources for Latin.
This WP aims to provide the Knowledge Base with its backbone, i.e., linguistic data-sets.
Work Package 2 (months 16-52). Building the Knowledge Base.
This WP represents the core of the project, as it aims to model the linguistic resources for Latin collected and selected in WP1 to build the Knowledge Base. Furthermore, this WP aims to make NLP tools for Latin interoperable and to connect them with linguistic resources in order to exploit the empirical evidence these provide for different NLP purposes.
Work Package 3 (months 33-52). Querying the Knowledge Base.
This WP intends to build a user-friendly interface to allow users to write and run SPARQL queries on interconnected linguistic resources.
Work Package 4 (months 45-59). Testing and Evaluating the Knowledge Base.
This WP tests the Knowledge Base by conducting research on its (meta)data.
Work Package 5. Disseminating the Results.
This WP is devoted to the dissemination of the results of the project through publications, conference presentations, tutorials and workshops.
Going FAIR
LiLa meets the so-called FAIR Guiding Principles for scientific data management and stewardship, which state that scholarly data must be Findable, Accessible, Interoperable and Reusable.
FINDABLE
For them to be discoverable, the (meta)data collected/created by LiLa are assigned a globally-unique and persistent identifier (Uniform Resource Identifier= URI). In LiLa, identifiers are meant to capture the different degrees of granularity of the (meta)data available in the resources, ranging from the most generic (e.g., the type of resource) to the most specific, such as the single occurrence (token) of a word (type).
Beyond elements belonging to a given resource, LiLa assigns URIs to (a) lemmas and word types (i.e., the different inflected forms a lemma can take), and (b) metadata. As for (a), each component of an open-ended list of lemmas (as well as of types) for Latin is assigned a URI, so that lemmas/types become uniquely-identified objects, which can be used as pivot nodes connecting their occurrences in various linguistic resources. With regard to (b), each tag representing a specific kind of metadata (e.g., NOUN and VERB for parts-of-speech) is assigned a URI, so that enhancing a token with metadata means establishing a relation between the token (with its URI) and the tag representing the metadata (with its URI), thus clearly and explicitly including the identifier of the data it describes.
Two main types of metadata are provided to help users identify and discover the data:
- linguistic metadata: lemmatisation, PoS-tagging, and possibly others provided by the individual resources, such as syntactic annotation in treebanks;
- relational metadata: explicit (and labelled) links between the objects of the Knowledge Base, which makes it possible to browse resources stored in different places and recorded in different formats.
ACCESSIBLE
To make (meta)data retrievable by their identifier, a standardised communications protocol is used, namely the widely adopted Hypertext Transfer Protocol (HTTP) for distributed, collaborative, and hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web.
In particular, (meta)data can be accessed via SPARQL, an RDF query language able to retrieve and manipulate data stored in the RDF format.
Since LiLa (meta)data are (a) distributed using a standardised protocol, (b) assigned standardised URIs, (c) accessible via a widely-adopted query language and (d) interlinked through a standardised vocabulary for knowledge description, they can be easily reused in other contexts. Furthermore, URIs help to track citations and the reuse of (meta)data.
The data and associated metadata, the documentation and the code are all deposited in the Zenodo research data repository, which warrants effective data curation beyond the lifetime of the grant.
INTEROPERABLE
Interoperability is the key-concept of LiLa, whose objective is to connect and support interaction between linguistic resources and NLP tools for Latin.
In LiLa, (meta)data include authoritative references to other (meta)data. These are provided in terms of explicit relations between the objects of the Knowledge Base, with the aim of helping users to identify and discover the (meta)data. Such relations are described by using a formal, accessible, shared, and broadly applicable language for knowledge representation described in vocabularies following the FAIR principles. These vocabularies are already implemented and used in the semantic web, and particularly in the Linguistic Linked Open Data cloud. More specifically, LiLa makes use of (and possibly extends) standard ontologies, formalisms, data models and linguistic data categories.
REUSABLE
In principle, there is no restriction as to who will be able to use the LiLa Knowledge Base. Anyone with an Internet connection is a potential user of LiLa.
To support (and increase) the reusability of LiLa’s (meta)data, these are described with a plurality of accurate and relevant attributes. Specifically, the use of a widely-adopted system of URIs, such as CTS URNs, helps to provide fine-grained references to text passages and single tokens alike, while meeting domain-relevant community standards.
One of the tenets of LiLa (and, more generally, of the Linked Data paradigm) is that providers keep their (meta)data locally. The LiLa Knowledge Base acts as a connection hub for these locally-stored resources. This requires that all (meta)data be accompanied by detailed provenance information and released under a clear and accessible data usage licence defined by each provider. Like all other providers, private publishing companies are free to impose restrictions on the use of their (meta)data.
The new (meta)data generated by LiLa are distributed under a CC BY-SA License. All software produced will be released under a GNU Lesser General Public Licence version 3 (GNU LGPL3). Unless otherwise specified, Zenodo metadata may be freely reused under the CC0 waiver.
1. Paul Tombeur. 1998. Thesaurus formarum totius Latinitatis: a Plauto usque ad saeculum XXum. Brepols, Turnhout, Belgium.